
Algorithmic AI ARIMA Trading Tool
May 16, 2022

"Algorithmic AI ARIMA Trading Tool": Upon first glance, this tool seems frighteningly difficult to understand. Furthermore, as you delve deeper into understanding the tool, various notoriously intimidating concepts begin to pop up: time-series forecasting, autoregression, moving averages, and machine learning, or ML, among others. However, when we break it all down, it really comes down to one simple concept: ARIMA modeling is a way to predict future values in a set of data that changes over time, like stock prices or temperatures, by looking at its past patterns and how it moves up and down.
As my first ever foray into finance-related ML, I too was extremely confused at the beginning of the project, which I completed with three other teammates for a "Projects in Programming and Data Science" class at NYU Stern. My teammates and I had the option of choosing much less complex projects and playing it safe, but we all agreed that since we were in a unique position where we had autonomy over project choice and difficulty while being in a constructive academic setting, we would "shoot for the moon" and put everything we had into the project for 4 months. I am very proud of how our project turned out, so let's dive a little deeper into the project specifics.
Project Description:
The goal of the program was to predict stock market prices using a Time Series Analysis and ARIMA model, with the output geared towards education on the step-by-step process of the analysis. As a result, we had three major components we wanted to include: an educative section explaining how the model works, a working ARIMA model, and a built-in back-tester.
Education: Our project provided an educational approach to trading strategies using a Time Series Analysis. The program's output was presented in an educative manner, showing step-by-step how the ARIMA model works, how the predictions are made, and how the trading strategy operates. The output also included visualizations of the data and results, making it easier to understand for users who are new to Time Series Analysis and trading strategies.
ARIMA Model: The core of our program was based on the ARIMA (AutoRegressive Integrated Moving Average) Model, which is a statistical model used for time series analysis and forecasting. We first gathered data from the stock market using pandas-datareader and created a pandas DataFrame object. We then implemented the ARIMA model and predicted future stock prices based on the time series analysis. Our program also focused on trading strategies by using the ARIMA model's predictions to make buy or sell decisions. What does a career in web design involve?
Back-tester: Our program also backtested the program over a period of time using historical data to verify the success of our trading strategy.
What is ARIMA Modeling?
Let's take a second to understand what ARIMA modeling is, using a description I shamelessly used ChatGPT to help create:
ARIMA (Auto-Regressive Integrated Moving Average) modeling is a powerful statistical method used for analyzing and forecasting time series data, which are sequences of observations taken at equally spaced intervals. It's particularly useful for understanding and predicting patterns in data that change over time, such as stock prices, sales figures, weather conditions, and more.
ARIMA modeling involves three main components: Auto-Regressive (AR), Integrated (I), and Moving Average (MA). Let's break down each of these components:
AutoRegressive (AR): This component considers the relationship between a current data point and its previous values. In simpler terms, it assumes that future values of the time series are influenced by its own past values. The "p" parameter in ARIMA represents the number of lagged observations used for prediction.
Integrated (I): The "I" part of ARIMA refers to differencing the time series data to make it stationary. Stationarity is important because it stabilizes the statistical properties of the data, making it easier to analyze and model. Differencing involves subtracting each observation from its previous observation to remove trends or seasonality.
Moving Average (MA): The MA component considers the relationship between a current data point and past forecast errors (the difference between predicted and actual values). This component helps account for any unexpected fluctuations in the time series. The "q" parameter in ARIMA represents the number of lagged forecast errors used for prediction.
Putting these components together, an ARIMA model predicts future values by combining past observations, their relationships, and the differences between predicted and actual values.
The choice of "p," "d," and "q" values (representing the order of AR, I, and MA components) depends on the characteristics of the data. Selecting appropriate values is crucial for accurate forecasting. This selection process can involve visual inspection of the data, statistical tests, and domain knowledge.
Datasets:
We accessed our datasets using a combination of API scraping and import modules in Python. In order to get accurate by-the-minute data on cryptocurrencies, we scraped a public API from Bitfinex, giving us data that looked like this:
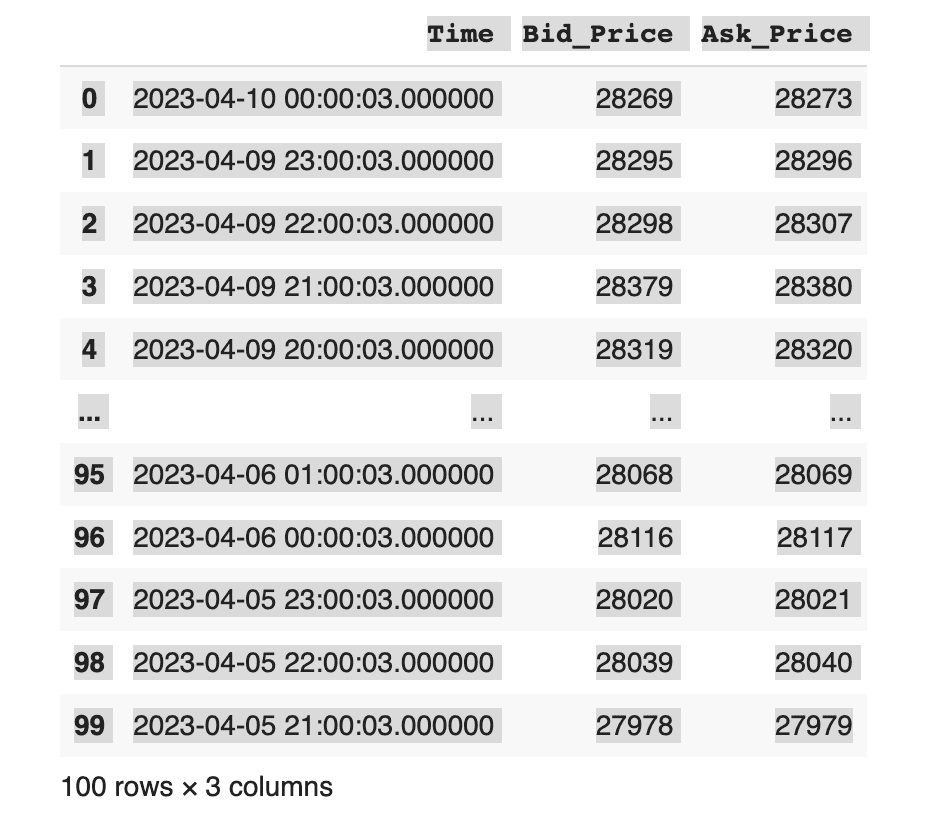
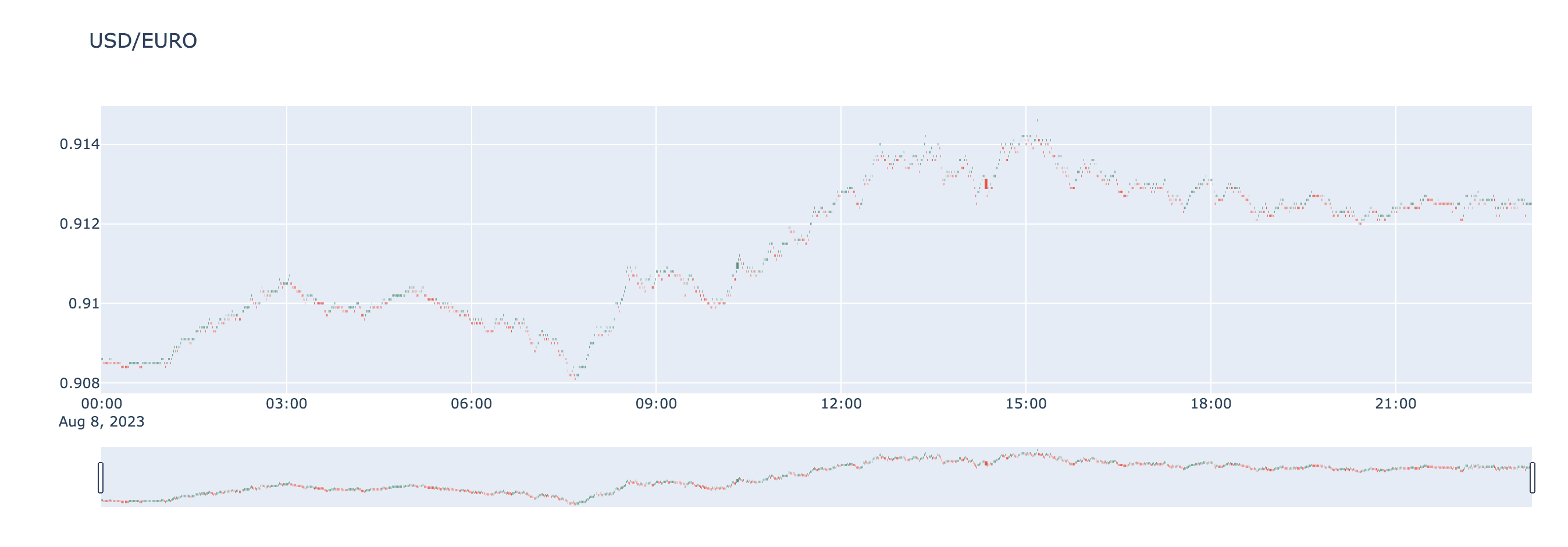
In order to get similarly accurate data on stocks and currencies, we used the existing yfinance module, allowing us to see data in a graphical fashion like below using data from Yahoo Finance:
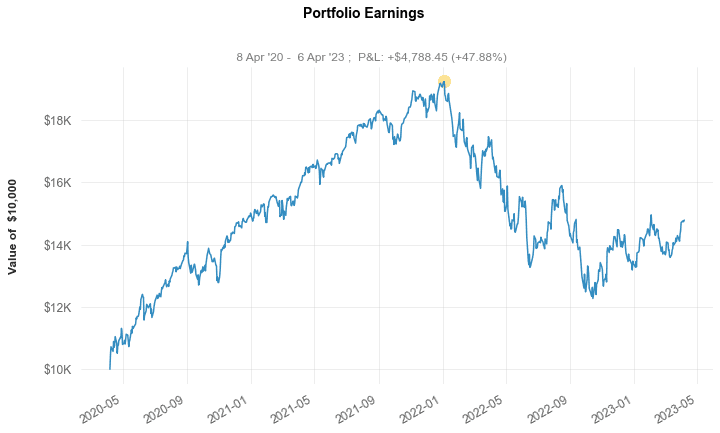
Finally, our third major data source was quantstats, another module which allowed us to plot portfolio performance like so:
Code Explained:
Backend - In this project, the backend collected financials that were used for the ARIMA model. Additionally, it generated parameters, analyzed the data, and used the model to compute predicted prices. Lastly, it tested the predicted price against real data, as well as offered an option for live testing.
Data Preprocessing - This component processed the available data from yfinance and organized it into a Pandas DataFrame. It included code that tested and turned the initial data into stationary data, and outputted the parameter "d."
Model Fitting - This component used SKlearn to train the data so that the model did not overfit. The data was used to assign three variables for the ARIMA model, "p" and "q." The three parameters were used in the ARIMA model to predict new prices. The newer prices were then stored in a table that was rearranged into one single column for easy comparison with the actual price. Calculations were done and stored in the Pandas DataFrame for error calculation and profit and loss.
Model Visualizations - This component visualized the data in a way that provided insight about the ARIMA model. This included plotting the ACF and PACF, predicted price against close price, profit and loss, as well as residual plotting, to ensure that residuals were normally distributed.
Frontend - In this project, Django was utilized as the web framework to construct a web application. It handled, among other things, routing, middleware, databases, and templates, making it easier to construct scalable and maintainable online applications.
dashboard.html - This code defined the structure and content of a dashboard webpage. The webpage had a title "Dashboard" and consisted of four sections, each containing a graph and some text. The four sections dealt with four currency pairs, each presenting different ARIMA parameters. The text included explanations of the strategy, recommended parameter selection, and profit ratio of a currency pair with visualizations.
audjpy.html - This was a step-by-step explanation of how the "Non-Seasonal ARIMA" model was utilized for the AUD-JPY currency pair. The page contained two images that illustrated the different parameter selection steps. The first image showed an example of an Autocorrelation Function (ACF) plot and Partial Autocorrelation Function (PACF) plot, while the second image showed an example of an ACF and PACF plot for a model with a single spike at lag 1. usdcad.html, usdjpy.html, usdeuro.html followed the same structure but for different currency pairs (USD-CAD, USD-JPY, USD-EURO) and parameters.
home.html - This code defined the homepage for the project. It allowed the user to select a program by clicking a button.
Research Modules:
statsmodels.tsa.stattool - Time-series analysis tools, including the Augmented Dickey-Fuller test for determining stationarity in time-series data.
statsmodels.tsa.arima.model - Time-series forecasting using the ARIMA model.
warnings - A built-in module in Python that provides a way to control warning messages that are issued by Python code. The warnings were set to be ‘ignored’ so that the ARIMA model could run.
statsmodels.api - A Python module that offers classes and methods for statistical modeling and analysis, such as time-series analysis. Autocorrelation and partial autocorrelation plots are provided as charting tools.
pmdarima.arima - A module that implements the ARIMA time-series forecasting model.
sklearn.model_selection - Provides model selection and hyperparameter tweaking tools for several types of models, including time-series models.
mplfinance - A matplotlib package for visualizing financial data, including candlestick charts and technical indicators.
Possible Project Enhancements:
Our project is by no means perfect, and there are definitely quite a few improvements that we could have and would have put into place if we were not restricted by a time constraint:
config.py - This code interacts with the stock market and fetches the API and Secret API of the alpaca account.
new.py - This code restructures the backend so that only one value of the predicted price is returned.
lumibot_arima.py - This will use the returned predicted price from new.py and compare it to real time data. If the predicted price is above current price, a buy order will execute. If the predicted price is below current price, a sell order will execute. A new predicted price will be called every minute.
Increase Analysis Techniques - More analysis techniques could be used, like GDP, inflation rate, or clustering.
Lumibot and Quantstats - integrate backtesting code to lumibot and quantstats for better front end visualizations.
User Interactivity - Allow the user to input more parameters, such as the range of years for unemployment or allow the user to create their own strategy. Additionally, allow the user to test their own datasets against our ARIMA model. This can be done in the data preprocessing section, to allow more variety of data. In the front end, more error detection can be implemented to not cause code to crash.
Real-Time Visuals - Components of the front end uses pre-downloaded png images to show the user the results of the ARIMA analysis. Using code to generate the graphs in real-time could be more accurate.
We also identified multiple components of the backend that could be improved. More research needs to be done to answer questions about the efficiency of the model. These include:
How stable are the parameters for the model during live testing? Is it required that with every new data, testing must be redone to generate new parameters?
What is the optimal opportunity cost between processing more data or getting more accurate predictions?
How can the data be manipulated to better suit the ARIMA model (no longer have ValueWarnings?)
Conclusion
Overall, despite the steep learning curve, this project gave me a strong introduction and backbone when it comes to finance-based ML. It also helped me understand the linear algebra behind many ML concepts and forced me to learn how to code dynamically using Python. Of course, I still have a lot to learn, and something I've been wanting to look into is risk optimization and fraud detection. As of right now, however, I'm not completely sure what my next project will be, so stay tuned!